StackLab
Deadline:2024-11-22 23:59:59
〇、实验简介
栈帧相关实验。
本学期,我们将金老师ICS第三个Lab回炉重造,添加更多讲解,以加深各位同学对栈帧的理解,并探索一些相关应用,丰富同学们的知识面。
本次Lab由三个部分组成:
- 尝试在含有漏洞的程序中实现任意代码执行
- 学习 Canary 机制,了解栈溢出的防御
- 尝试使用栈帧完成更多有意思的功能(参考资料:2022年Kieray Lab)
一、危险的计算器
RCE 攻击
电影中的黑客神通广大,能神不知鬼不觉地“黑”掉各种计算机系统,他们是如何做到的?
首先,我们需要认识一下“黑”掉一个系统到底是指什么,对于黑客来说,有许多种不同的攻击效果(或者说漏洞):
- RCE (Remote Code Execution):远程代码执行,即攻击者可以在远程服务器上执行任意代码;
- DoS (Denial of Service):拒绝服务,即攻击者可以让服务器无法正常工作;
- MITM (Man-In-The-Middle):中间人攻击,即攻击者可以在通信过程中窃取信息;
- ……
其中,攻击者最为喜闻乐见的就是RCE,因为这意味着他们可以在服务器上执行任意程序代码,做任何自己想做的事。比如,他可以把网站服务器托管的网站的首页改成自己的名字;又比如,他可以在上面运行自己的挖矿程序,借用他人计算机的算力帮自己牟利。
一个最简单的RCE漏洞形如:
1 | read(0, input, 20); |
这段代码读取用户输入,并调用了 system
函数。system 函数的功能是执行一条shell指令,比如
system("ls") 就会相当于在命令行上输入 ls
以显示当前目录下的文件。
这个程序在本地运行时,显然没什么问题,但如果这个 input
字符串来源于网络,这意味着攻击者可以通过输入恶意指令来执行任意代码。比如,当类似于这段代码的程序运行在一个服务器上时,攻击者只要想办法控制input为
rm -rf / 就可以删除服务器上的所有文件。
所以,RCE 通常就是指“在目标机器上执行任意shell指令”。
栈溢出漏洞
栈溢出漏洞是一种常见且经典的漏洞,破坏力非常强大——它经常可以使攻击者达成 RCE。
栈溢出漏洞在C语言当中非常常见,主要是因为使用 C 语言时非常容易漏掉对数组边界和 buffer 大小的检查。比如,下面这段代码:
1 | char buffer[20]; |
这段代码使用了 gets 函数,它会读取用户输入并存储到
buffer 中。然而,gets
函数并不会检查用户输入的长度,如果用户输入的长度超过了
buffer
的大小,就会导致多余的数据“溢出”到栈上的其他位置,导致其他数据被干扰。这就是栈溢出的定义。
从栈溢出漏洞到劫持程序控制流
之所以栈溢出漏洞如此危险,是因为它可以被利用来劫持程序的控制流。我们来回忆一下,栈上有哪些数据?
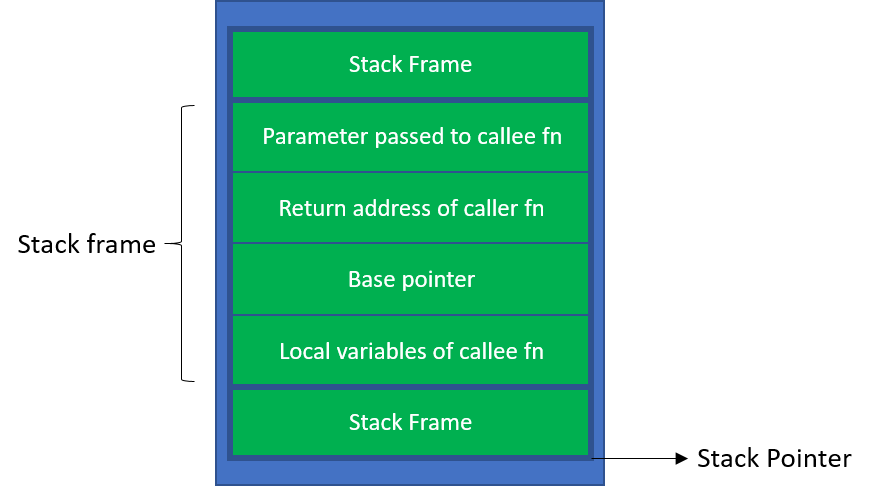
注意到,其中有一个重要的数据:返回地址。当函数调用结束时,程序会跳转到这个返回地址继续执行。
如果攻击者栈溢出的数据控制了这个返回地址,他就可以决定程序接下来返回到哪里,从而控制程序的执行流程。
在劫持了程序控制流之后
“决定程序接下来执行哪个函数”,这听起来是不是很像我们之前说的RCE?没错,这就是栈溢出漏洞的危险之处:它可以被利用来实现任意代码执行。试想,如果程序中存在一个调用
system("/bin/sh")
函数的地方,我们只需要把对应的地址填到栈上返回地址的位置,就可以控制程序去调用
system("/bin/sh"),从而获取一个 shell 达成 RCE。
聪明的你可能会问:并不是所有的程序都会调用
system("/bin/sh")
或是类似的函数,这种情况怎么办呢?我们现在仅仅能够控制程序接下来执行哪个地址的代码,离执行任意的shell指令还有一段距离。
这个时候就需要进行“构造”了,攻击者在利用漏洞时,需要利用好一切可以利用的资源,包括但不限于:当前寄存器中的数据、内存中的机器码和数据等等。
比如,我们知道 rdi
寄存器是用来传递第一个参数的寄存器。如果我们劫持程序控制流到
foo(int a) 函数,其实就相当于调用了
foo(<当前rdi值>)。
又比如,我们不一定要控制程序去返回到某个函数(的起始位置),而可以控制程序返回到某个函数的中间。如果有这样一个函数:
1 | void foo() { |
看上去这个函数没有任何用。但其中包含的 system("/bin/sh")
片段可以为我们所用:我们可以直接控制程序执行 if 内的代码。
实验
在本次试验中,我们给出了一个简单但包含有漏洞的计算器程序,它会读取用户输入的表达式,包上
echo $(()) 后调用 system
函数来计算表达式的结果。
你的任务是:利用栈溢出漏洞,控制程序执行 ./malware
。这个“恶意程序”会检测自己的父进程调用,如果发现自己由
bash-calc 调用,就会输出
You have successfully detonated the bomb! Congratulations!,表示你已经成功完成了任务。
实验步骤
- 阅读
bash-calc.c源代码,理解程序的逻辑,找到漏洞所在函数,计算出溢出所需要的字符数; - 使用
gdb调试程序,将断点设置在漏洞所在函数的ret语句处,观察此时各个寄存器的值; - 结合你的观察,构造一个恰当的 payload,使得程序执行
./malware;
提示
不同输入函数的“截断”不同,截断指的是输入函数在读取到哪些字符时会停止读取。比如,
gets函数会读取到换行符为止,所以它也会读入\0这种非常特殊的字符。具体可以参照 CTF中常见的C语言输入函数截断属性总结一个示例的构造payload的方法:
假设buffer距离返回地址的偏移为0x10,且我们想让程序返回到地址
0x4005d6,则我们可以编写一个如下的 Python 程序:
1 | import sys |
然后在终端中执行:
1 | python3 payload.py | ./bash-calc |
或者直接将 payload 写入文件,然后使用重定向机制:
1 | python3 payload.py > payload |
后者可以帮助你在使用gdb时更好地调试,比如在gdb中执行
run < payload 就可以使用终端的重定向语法。
- 我们的目标类似于执行
system("./malware"),如果你已经构造成功了 payload 使程序执行system("./malware"),但程序在system函数的内部崩溃了,这在我们的预期内。
造成这种情况的原因是:system
内部某些汇编语句对栈的对齐要求很高,如果没有对齐至
0x10,就会导致程序崩溃。如果你使用gdb进行调试,你就可以看到这几条非常“挑剔”的汇编指令。
在正常执行一个函数时,rsp 寄存器是向 0x10
对齐的;调用某一个函数时使用的是 call
指令,会往栈上压入一个8字节的返回地址(这里就破坏了对齐),然后跳转到函数的起始位置。因此,每个函数都会假设自己刚刚被调用时,rsp
寄存器是不向 0x10 对齐的。
然而,我们通过劫持返回地址调用某个函数时,我们并没有使用
call
指令,而是直接跳转到了函数的开头。这就导致函数开始时,栈反而向 0x10
对齐了,这破坏了 system 函数的假设,导致程序崩溃。
解决办法很简单:不要直接调用 system
函数,而是调用一个中间函数,并且跳过函数开头的一条 push rbp
指令。这类似于手动破坏栈的对齐,使得 system
函数可以正常执行。关于这个解决方法的原理分析,我们留作思考题。
实验之后的思考题
除了在报告描述你的攻击流程之外,你还需要在报告中回答以下问题:
Problem 1.1 实验任务中导致溢出的函数早就成为了一个臭名昭著的函数,现如今几乎没有人会再使用它。但即使在 2024 年的今天,我们依然会看到许许多多的栈溢出、堆溢出漏洞。请你思考一下,还有什么其他的场景、函数会导致溢出?你自己是否在编程中遇到过栈溢出的情况?
Problem 1.2
提示中提到了一个解决方案:不要直接调用 system
函数,而是调用一个中间函数,并且跳过函数开头的一条 push rbp
指令。这类似于手动破坏栈的对齐,使得 system
函数可以正常执行。请你思考一下,为什么这样做可以解决问题?
二、栈溢出的防御
有一种针对于栈溢出的防御机制被广泛部署于各种软件中,也早已被作为编译器的默认选项。
在这个任务中,我们需要你重新编译
bash-calc.c,通过阅读汇编代码的方式,理解这种防御机制的原理。
你可以使用这条指令来重新编译一个 bash-calc-my:
1 | gcc -no-pie -o bash-calc-my bash-calc.c |
在编译以后,你可以通过两种方式来探索这种防御机制:
- 借助gdb动态调试,使用刚刚的 payload 攻击程序,观察程序的行为;
- 借助objdump静态分析,观察程序新增加的汇编代码,通过搜索等手段理解其意义。
你需要在实验报告中描述你对这种防御机制原理的理解,并尝试回答一个问题:
Problem 2.1 这种防御机制是否能够彻底“防御”栈溢出漏洞?
三、栈帧的更多应用(协程)
在前两项任务中,我们已经加深了对程序运行时的栈帧的认识,接下来,我们使用栈帧和一定的汇编语言,来给C语言实现一些更加现代的功能吧。
在本实验中,你可以在Task3文件夹下,使用make clean && make来编译代码,使用./program来运行代码。
前言
在本实验中,你并不需要清晰地知道进程和线程的区别。你可以理解为一个进程可以开启多个线程,让CPU的不同核心同时计算不同的功能。
如果在程序运行的过程中,我们直接将PC(%rip)的值修改到某个指定地址,那程序大概率是不能正常运行的。比如我们尝试编译这样一个简单的二分查找C语言程序:
1 |
|
它的main函数反汇编后如下:
1 | 0000000000001202 <main>: |
Problem 3.1 在运行main函数时,内存-0x4(%rbp)处是什么?1217位置的mov语句是为了做什么?
Problem 3.2
二分查找函数中我们使用了register int保留字,这告诉编译器要把变量存到寄存器而不是内存中,这样做有什么好处1?正因如此,在执行完二分查找函数中的算法部分,希望返回主函数时,能否直接修改%rip的值到1221而不做其他事情?还缺少什么步骤?
[1]实际上在现代编译器中,你不需要自己手写register关键字。开启优化后,编译器会自动安排变量的位置,找到最优化的一种策略,这基本是现代编译器必备的操作。
上下文保存与恢复
打开Linux终端,输入top -H指令(按下q退出),看看当前电脑上正在运行的线程有多少个?再输入cat /proc/cpuinfo | grep processor,看看你的电脑的CPU有多少个线程?
在大部分情况下,系统中正在运行的线程数量都比CPU的线程数要多,但是你可以试试播放同时多个视频、音频、下载文件、编辑文档、QQ微信接收消息、显示动态壁纸……CPU可以“同时”做到这些事情。想要实现这个效果,自然不能让一个程序线程独占一个CPU,也就是——限制线程能连续在CPU上运行的时间,时间用完后切换到一个其它的线程继续运行。只要这个连续运行时间足够短,在我们看起来,电脑就是在同时进行所有工作。
上面这段文字暗含了一些信息:电脑需要保存一个线程“执行到什么状态了”,这样它下次继续运行该线程时可以直接从暂停的位置继续。我们将这个执行的状态称之为上下文,这两种操作分别称为保存上下文和恢复上下文,记为save和restore。本实验我们将这些操作限制在同一个进程内,同学们不需要考虑硬件和操作系统层面的内容。
Problem 3.3 结合Problem3.2,为了让程序能在跳转到指定位置后正常运行,我们除了修改%rip,还需要复原__的状态。所以,save操作需要将这些信息记录到内存中。
我们在这里规定save操作不记录函数的栈帧。想象一下用户在函数中申请了一个16MB的数组,如果save记录栈帧,一次调用就需要将整个数组都复制一遍,低效且浪费空间。
实际上,对于当前save和restore的定义,我们还有两个需要考虑的方面。对于如下的伪代码:
1 | funcA: |
Problem 3.4 假如变量x被存放在栈帧上,在restore操作后,x的值为__;假如变量x被存放在寄存器上,在restore操作后,x的值为__。
由于变量放在寄存器还是内存是由编译器决定的,根据编译器策略的不同,可能会导致同一份代码产生不同的运行结果。为了简化问题,我们可以做出如下限定:在save语句后修改过的局部变量,在restore后都是未知的,让开发者不要在restore之后直接使用这些变量的值。
此外还有一个问题。我们可以模拟这个过程:程序首先在funcA中save一次,调用funcB,restore后程序复原到save时的状态,又回到x=1这条指令。接下来程序又调用funcB,又执行一次restore,这显然不是我们所期望的。
为了避免这种“死循环”,我们可以给save添加一个“返回值”:正常save函数返回0,程序继续向后执行;而执行restore后,程序的执行位置同样会回到save的后一条语句,其表现也像是“在save后返回到该函数”,只需要让此时save的返回值表现为非0(想一想,函数返回值的本质是什么?),就能区分开save和restore。甚至,为了让该功能更加实用,还能用一些枚举值来表示“程序为什么调用了restore”。
1 | funcA: |
接下来,我们将通过汇编实现save和restore的功能(显然,不考虑汇编和调用库函数的纯C语言难以实现这个功能),不过在此之前我们先着手用汇编语言写一个简单的函数吧。
Problem 3.5
请用不超过5条汇编指令2实现函数naive_func,直接写在实验报告中。该函数的功能为:将函数的返回地址保存到第一个参数所指定的内存地址,然后返回0。可参考伪代码:
1
2
3naive_func(void **p):
*p = (return addr);
return 0;
[2]不计伪指令。如果可以,请在函数开头加上
endbr64,正确做法下指令数量是足够的。
Problem 3.6
也许你在课上学过函数开头两条指令的固定格式push rbp; mov rbp, rsp。但是前面所写的naive_func显然不遵循这样的格式,为什么这是可以的呢?
接下来,我们开始着手实现save和restore函数,为了实现更多后续功能,这两个函数的定义与上文所述有略微不同,请参见API手册。
Task 3.1
请在context_asm.S中实现函数__ctx_save和__ctx_restore,分别对应上文所述的save和restore操作。根据函数的定义,你需要仔细考虑哪些数据是需要存储到__ctx中的。你可以自行调整__ctx类型申请的内存大小,但是我们保证原始代码给出的120字节是足够的。如果一切顺利,在完成本节内容后,你将能通过
test1 和 test2。
按照 x86-64 调用约定,rdi 和 rsi 分别为函数调用的第一二个参数,rax 为函数调用的返回值。在默认情况下,gcc 使用 AT&T 汇编语法。如果你想要使用 Intel 汇编语法,可以在ctx.S的开头加上一句.intel_syntax noprefix。 禁止使用 setjmp 或 __builtin_setjmp 等现成函数,但你也许可以参考它们的实现。
基于上下文回退的异常处理
现代编程语言基本都支持异常处理机制,即程序包含以try和catch(或except等关键字)开头的代码块,程序员可以将一些代码放到try代码块中,如果遇到除0错误或是其他一些错误,程序不是直接停止运行,而是跳转到catch后面继续运行。
基于上一部分已经实现的两个操作,我们可以实现一个简单的异常处理机制,不妨参考下面的伪代码:
1 | func(): |
这实际上等同于使用try-catch机制,它和下面的Python代码是基本等价的:
1 | def func(): |
借助C语言的宏,我们可以将原始含save和recover的代码包装成类似Python或者C++风格的代码。而且,try-catch是可以嵌套的。在发生try-catch嵌套时,程序中会同时存在许多个try记录的上下文。在执行throw操作时,我们需要恢复到最新的一个上下文,如下面的C++代码:
1 | try{ |
该代码会输出1。
容易看出,这实际上就是一个栈的结构,我们将其称为异常处理栈。对于每个try操作,它记录当前的上下文,并将其加入异常处理栈。对于每个throw操作,它弹出异常处理栈中的栈顶元素,将当前状态恢复成该上下文,并转而执行catch操作。当然,清理也是必须的,对于每个正常完成的try操作,我们需要弹出异常处理栈中的栈顶元素,使之恢复到try操作之前的状态,如下面的代码则会输出2:
1
2
3
4
5
6
7
8
9
10
11try{
try{
}
catch{
cout << 1;
}
throw Exception;
}
catch{
cout << 2;
}
在本lab中,我们采用单向链表的方式来实现这个栈。在该Task中,你暂时不需要考虑__generator结构体的作用,只需要知道__now_gen->__err_stk_head是这个单向链表的表头,__err_stk_node结构体用于表示链表的节点。你需要实现__err_stk_push和__err_stk_pop两个函数来实现链表的操作,然后使用我们当前已实现的功能,填充try、catch和throw的宏定义3。
[3]C语言提供了cleanup属性,被添加该属性的变量会在生命周期结束时执行对应的函数,可以理解为类似析构函数的功能,可参考https://gcc.gnu.org/onlinedocs/gcc/Common-Variable-Attributes.html
Task 3.2
请在context.c中实现函数__err_stk_push和__err_stk_pop,然后在context.h中实现try、catch和throw的宏定义。如果一切顺利,在完成本节内容后,你将能通过test3、test4和test5。
基于上下文切换的生成器(协程)
如果你还不熟悉Python的生成器,可以试着跑一下以下程序,观察输出:
1 | def test(x): |
这段代码里面有关键字yield和方法send。当gen被赋值为一个函数后,程序并没有执行该函数。而第一次调用send方法时,程序跳转到该函数的开头开始执行,执行到第一个yield关键字时,函数将yield后面的值作为send方法的返回值,恢复到调用send的地方继续向后执行。下次send又被调用时,程序并不是在函数中从头开始,而是接着上次yield的位置继续向后执行,且send方法的参数在该函数看来就是yield的返回值。当test函数执行完毕后,程序会抛出一个异常。
这似乎跟我们前面实现的保存上下文很像:yield保存了函数当前的上下文,返回主函数;send保存了主函数的上下文,恢复函数的上下文继续执行。看起来这个功能似乎很好实现?不过先让我们看看下面的伪代码:
1 | ctx a, b; |
容易看出,如果这段代码已经跑起来了,它可以交替执行 A 和 B 两个循环,只要在此基础上包装出 yield 和 send 函数,即可达到与 Python 中生成器一致的效果。但我们首先要解决一个问题:它是怎么跑起来的?
请注意我们在之前提出的约定:函数返回之后,不能再使用其调用save保存的上下文。因此,要想使funcA中引用的ctx
b有效,必须保证funcB不返回(保证不清除栈帧),这似乎只可能发生在funcB调用了funcA的情况下。但反过来,要想使funcB中引用的ctx
a有效,也必须保证funcA不返回(保证不清除栈帧),似乎只可能发生在funcA调用了funcB的情况下。
上面的分析仿佛引出了一个悖论。事实上,这一悖论只会在funcA和funcB使用同一个调用栈的情况下成立。假如我们为funcA和funcB分配两个不同的栈空间,那么执行funcA时,funcB的栈帧保留在它自己的栈空间上,与funcA所在的栈空间并无关联,也就不需要调用关系来保证funcB不返回了。
为了实现多个栈空间,我们可以手动申请一块内存,配置一段自定义的上下文,然后通过我们实现的restore函数来更改寄存器的内容,并让程序跳转到这一段内存开始执行函数,这样这个函数就有了一段独立的栈空间。
总结一下这个过程:创建生成器时,程序申请一段内存,并在该内存中配置一段初始上下文,等待调用。当生成器第一次被调用时,restore到这段初始上下文,程序在你手动配置的返回地址的位置继续执行,从而跳转到生成器对应的函数,直到第一次遇到yield。此时程序保存当前生成器的上下文,返回到调用该生成器的函数中。如果生成器的函数执行完毕,抛出一个ERR_GENEND异常。
在已给出的__generator结构体中,我们使用data变量来传输yield和send的参数。为方便起见,我们将程序的主函数也视作一个generator(只不过你不需要手动给这个generator制作一个栈空间和初始上下文),因此全局变量__now_gen被初始化为了&__main_gen,且每个generator都有自己的异常处理栈。
Task 3.3
请在context.c中实现函数send,yield和generator(你可以理解为构造函数)。允许自行添加一些函数,因为你可能需要一些跳板函数来实现生成器的启动。你可能需要修改throw宏,以在外部处理生成器内部未处理的throw。如果一切顺利,在完成本节内容后,你将能通过test6和test7。
协程的一些实际应用
协程在现代应用程序中有广泛的应用。比如,手机程序向服务器请求数据时同时显示动画,就可以理解为本机的逻辑处理函数发送网络请求后,上下文恢复到主函数来显示动画,一旦服务器返回了数据,上下文又切换到逻辑处理函数来执行后续操作。这是非常节约资源的一个方法:开辟新线程来进行网络通信也可以达到相同的效果,但开辟新线程本身就会消耗一些系统资源,所以不是最优的选择。
本Lab最后一个部分希望你能自定义一个基于协程的进度条动画。考虑我们平时玩的游戏,游戏画面本身也是多张图片连续快速播放,人眼看起来就变成了连贯的动画,这一过程可以用以下伪代码表示:
1 | def game(): |
其中,delta_time代表游戏两帧之间间隔了多久,游戏场景里面的物件会根据这个时间间隔移动相应的距离。
当需要给某游戏物件做一个持续若干秒的动画时,我们不能在某函数中写一个循环,每次移动一点物体,然后sleep若干毫秒,循环直到动画结束,这会导致在动画结束前都无法执行到其它代码,会阻碍其他游戏事件的进行。一种解决方法时,开启一个新的协程,每次主函数向协程send(delta_time),协程就会根据时间变化量少量修改对应物体的坐标,然后yield回到主函数来执行其它代码,等待下一帧到来,主函数继续send,以此类推,直到动画结束。
这是在如Unity等游戏引擎中一种典型的通过代码来制作物体动画的方法。
Task 3.4
基于上面的讨论,请你完善main.c中的progress_bar函数,实现一个自定义的进度条动画。发挥你的想象力即可。
